Reproductibilité et controverses#

Élisabeth Loranger 🤔 |

Pierre bellec 🤔 |

Eddy Fortier 👀 |

Marie-Eve Picard 👀 |
Durant ce cours, nous avons effectué un survol de diverses techniques de neuroimagerie qui ouvrent une fenêtre fascinante sur la structure et la fonction du cerveau. Par contre, ces techniques sont régulièrement présentées dans des articles scientifiques qui semblent peu crédibles. Dans cet ultime cours, nous allons discuter des controverses entourant la neuroimagerie, et de façon plus large, de la crise de reproductibilité en sciences.
Les objectifs de ce cours sont les suivants :
Comprendre la crise de reproductibilité en sciences.
Comprendre certaines pratiques scientifiques douteuses qui participent au manque de reproductibilité en neurosciences cognitives.
Connaître certains outils qui peuvent améliorer la reproductibilité en neurosciences cognitives.
La crise de reproductibilité#
Une crise? Quelle crise?#

Fig. 109 Cette figure illustre un exemple de processus pouvant amener à un résultat scientifique controversé (ainsi qu’un exemple de problème de comparaisons multiples). Cette figure est tirée de xkcd webcomic, sous licence CC-BY-NC 2.5.#
En 2016, un sondage effectué auprès de 1576 chercheurs a été mené dans le but de voir si, dans la perception des professionnels dans la recherche, il y avait une crise de reproductibilité, et si oui, laquelle (Baker, 2016). En tout, 90% des chercheurs ont affirmé dans ce sondage qu’ils pensaient qu’il y avait effectivement une crise de reproductibilité (52% pour une crise significative et 38% pour une crise modérée).
La reproductibilité, c’est quoi? Si nous avions accès aux données derrière ce papier, serait-on capable de refaire les analyses et d’arriver aux mêmes conclusions? Un autre concept proche est la réplicabilité: en recrutant de nouveaux sujets (nouvel échantillon) et en faisant exactement ce que les autres chercheurs avaient fait au niveau des outils utilisés et des analyses effectuées, est-ce que nous trouverions les mêmes résultats? Dans le sondage, 70% des personnes sondées rapportaient avoir échoué à reproduire les résultats d’une autre équipe de recherche et plus de 50% d’entre eux rapportaient même avoir échoué à reproduire leurs propres résultats.
Les personnes sondées ont aussi évalué les causes probables de cette crise de reproductibilité. Parmi les raisons les plus fréquemment mentionnées, on retrouve la pression de publier, la publication sélective (les gens ne publient seulement que ce qui fonctionne bien) ainsi que la puissance statistique limitée. Ce chapitre cherchera à expliquer certaines de ces notions plus en détail en commençant par formaliser le processus de génération de connaissances scientifiques.
La méthode scientifique#
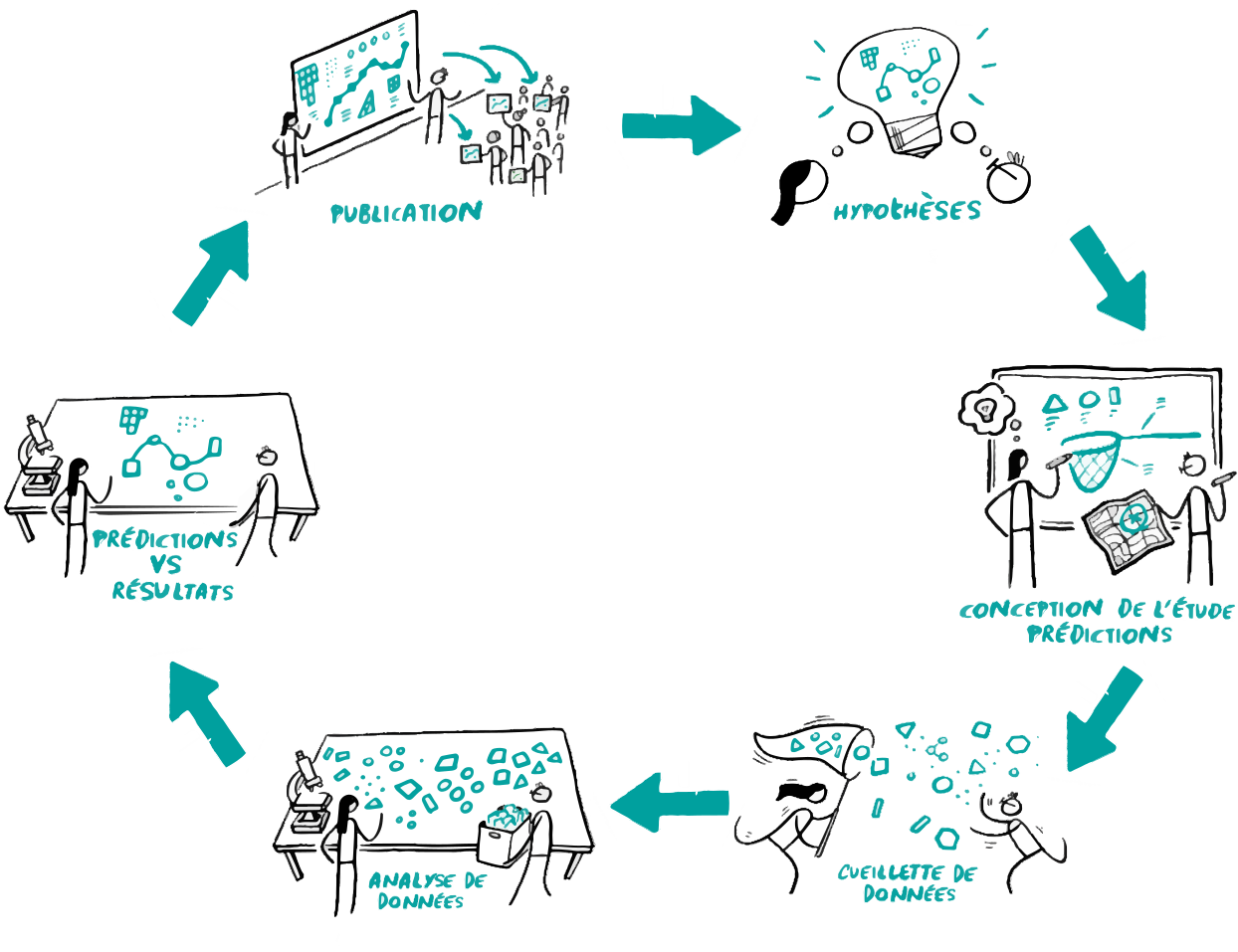
Fig. 110 Cette figure illustre le cycle des découvertes scientifiques selon l’approche de la méthode scientifique décrite par Karl Popper. Figure adaptée d’un travail original par scriberia dans le cadre du livre The Turing way sous licence CC-BY 4.0, DOI: 10.5281/zenodo.3332807. La figure adaptée par P. Bellec est elle-même disponible sous licence CC-BY 4.0.#
La Fig. 110 présente une version simplifiée de la méthode scientifique impliquée dans la découverte de connaissances, inspirée par la théorie de Karl Popper, telle qu’elle est généralement implémentée dans la communauté de recherche.
On commence avec une consultation des publications antérieures: celles-ci représentent les connaissances qui ont été accumulées par d’autres chercheurs avant nous.
En lisant cette littérature, les chercheuses/chercheurs peuvent prendre connaissance de ce qui a déjà été découvert et formuler des hypothèses en lien avec ce que l’on sait déjà sur des choses qu’on ne connaît pas encore.
Les chercheuses/chercheurs vont alors construire un devis de recherche: nombre de participants, groupes, tests statistiques, etc. Elles/ils vont aussi faire des prédictions concernant les résultats qu’elles/ils pensent obtenir.
Une fois le devis de recherche élaboré, il est maintenant temps de recueillir les données.
Ensuite, on analyse les données en suivant le protocole qui avait été établi dans le devis de recherche.
Il faut alors interpréter les résultats et notamment les comparer à nos prédictions pour valider ou invalider nos hypothèses.
Les résultats de la recherche sont alors publiés pour permettre au reste de la communauté de recherche de continuer à formuler de nouvelles hypothèses.
Comme on utilise des statistiques rigoureuses dans cette approche, on ne génère qu’une quantité limitée de faux positifs, et donc, on fait des découvertes scientifiques sans faire trop d’erreurs. En pratique, cette approche peut être adaptée de nombreuses manières en y incluant des pratiques de recherche douteuses qui vont compromettre l’intégrité et la rigueur des conclusions de l’étude.
La méthode scientifique: hacked#
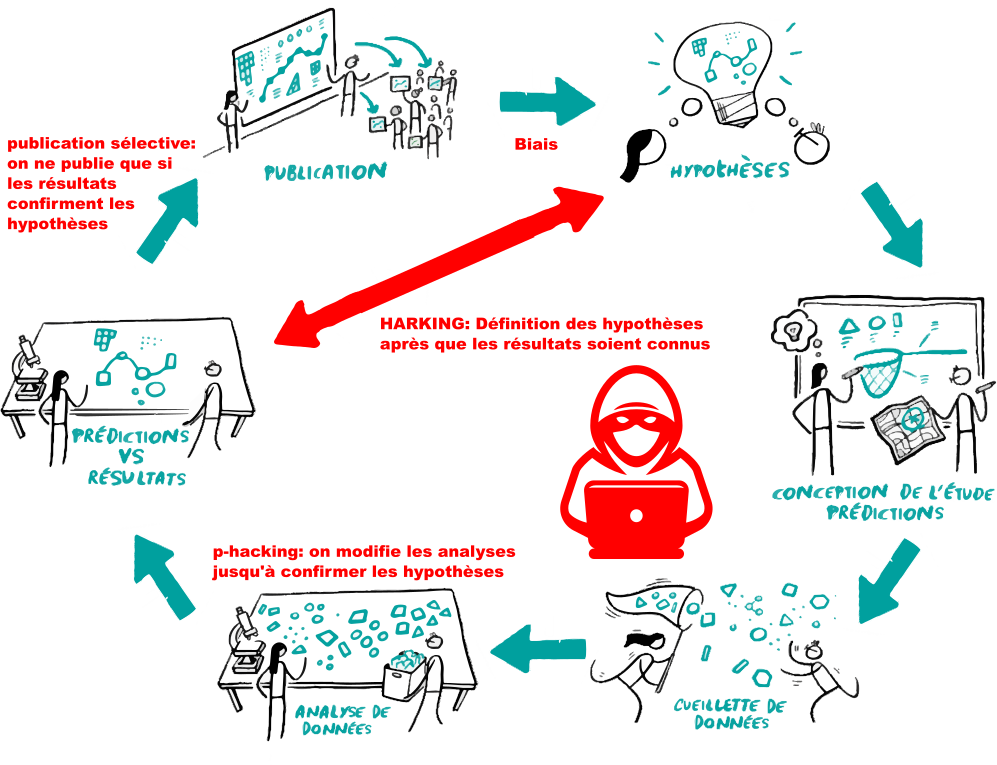
Fig. 111 Cette figure illustre les pratiques douteuses qui peuvent affecter négativement l’intégrité du cycle des découvertes scientifiques. Figure adaptée d’un travail original par scriberia dans le cadre du livre The Turing way sous licence CC-BY 4.0, DOI: 10.5281/zenodo.3332807. La figure intègre aussi une image shutterstock, utilisée sous licence shutterstock standard.#
Biais de publication#
La publication sélective est un des problèmes les plus importants identifiés dans le sondage vu plus tôt. Cela signifie que les résultats d’une étude ne sont publiés que lorsqu’ils sont positifs, c’est-à-dire uniquement s’ils confirment les hypothèses de l’équipe de recherche. Si ce type de pratique est systématique dans une communauté de recherche, il se peut que plusieurs groupes rapportent un résultat, qui semblera alors robuste, alors qu’en fait, un nombre plus important de groupes de recherche n’ont pas pu répliquer cet effet et ne l’ont donc jamais publié. Cela vient déformer complètement la collection de connaissances accumulée par la communauté scientifique, collection qui sera elle-même à l’origine des hypothèses des études futures.
p-hacking#
Si nous voyons que nos résultats ne correspondent pas à nos attentes, il est possible que nous nous demandions si nous avons commis une erreur ou si nous avons bien choisi la technique d’analyse optimale. Nous risquons alors de revisiter la manière à laquelle nous analysons les données jusqu’à ce que les résultats deviennent significatifs. Ce type d’approche a été baptisé p-hacking. Le p-hacking peut prendre de nombreuses formes: exclusion arbitraire de “valeurs aberrantes”, sélection d’un sous-groupe qui montre l’effet attendu, changement des paramètres de prétraitement, etc.
HARKing#
La dernière pratique douteuse est baptisée le « HARKing ». Le terme HARK est un acronyme originaire de l’anglais pour les termes « Hypothesis after results are known », ou bien “définition des hypothèses après que les résultats soient connus”. On va effectuer de nombreux tests à partir des données recueillies et on va formuler a posteriori des hypothèses correspondant aux résultats significatifs dans l’échantillon. Ce processus n’est pas nécessairement malicieux, mais il peut émerger d’une volonté d’interpréter les données à tout prix. Cette démarche n’est pas nécessairement problématique, du moment que les hypothèses sont (correctement) présentées comme étant de nature exploratoire, guidées par les données, plutôt que comme des hypothèses formulées a priori de façon rigoureuse.
Reproductibilité et neuroimagerie#
Nous allons maintenant voir comment la neuroimagerie représente un domaine particulièrement propice au p-hacking, ainsi que d’autres facteurs qui peuvent contribuer au manque de reproductibilité. Ces facteurs sont tous liés à la complexité des chaînes de traitement en neuroimagerie.
Tout d’abord, il est possible de faire varier de façon importante les conclusions d’une étude juste en modifiant les choix analytiques que l’on fait concernant la chaîne de traitement (ce que l’on appelle les degrés de liberté en recherche).
Ensuite, il est possible de confondre les effets significatifs et les effets importants (on doit considérer la taille des effets).
Enfin, à cause de la complexité des méthodes utilisées, il est souvent difficile, voir impossible, de vraiment comprendre les méthodes utilisées dans un article seulement sur la base du texte de cet article (méthodes incomplètes).
Degrés de liberté en recherche#
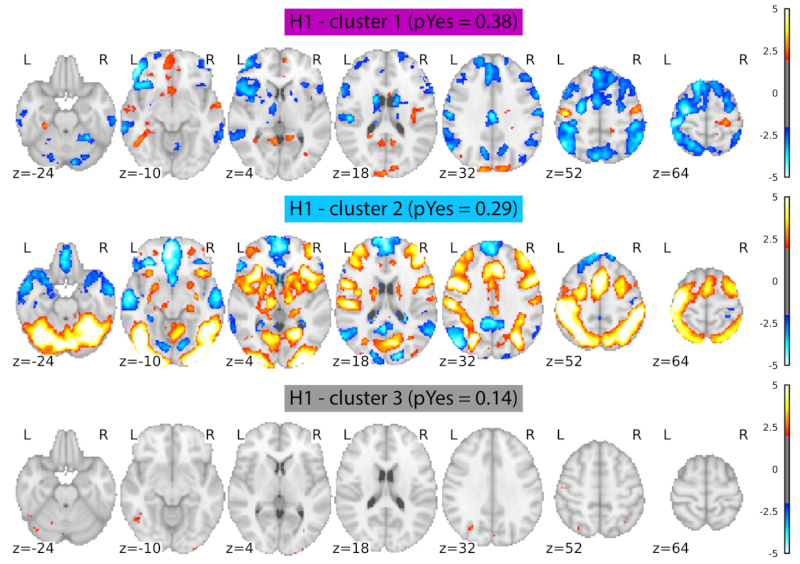
Fig. 112 Cette figure résume les cartes d’activations IRMf générées par 64 équipes indépendantes à partir des mêmes données et ayant pour objectif de tester la même hypothèse. Les équipes ont été séparées en trois sous-groupes sur la base de la similarité spatiale de leurs cartes d’activation à l’aide d’un algorithme automatique. Le premier groupe (cluster 1) est le plus gros, avec 50 équipes, alors que les deux autres sous-groupes incluent 7 équipes chacun. Notez les variations importantes entre les trois sous-groupes. Figure tirée de Botvinik-Nezer et al., 2020 sous licence CC-BY-NC-ND 4.0.#
Pour chacune des techniques étudiées dans ces notes de cours, il est nécessaire d’implémenter une série d’étapes d’analyse et de choisir certains paramètres pour chacune de ces étapes. Dans la mesure où l’on n’a pas de vérité de terrain à laquelle se référer en neuroimagerie, il n’existe pas de consensus sur le choix optimal concernant ces paramètres. De plus, ce choix est probablement dépendant de la population d’intérêt et des questions de recherche dans une large mesure. Pour quantifier cette variabilité, une étude récente a invité 70 équipes de recherche à analyser le même jeu de données par activation en IRMf Botvinik-Nezer et al., 2020 et à tester les mêmes hypothèses. Un premier résultat frappant est que chaque équipe a utilisé une approche unique pour analyser les données, illustrant ainsi le manque criant de standardisation dans le domaine. Un autre résultat frappant est que, pour une hypothèse donnée, certaines équipes ont produit des cartes très différentes (voir Fig. 112). Bien que certains sous-groupes d’équipes aient identifié des cartes très similaires, certains choix ont amené à des différences importantes. Par ailleurs, même pour les équipes générant des cartes similaires, leur interprétation de la carte pour répondre à l’hypothèse variait substantiellement!
Degrés de liberté en recherche et p-hacking
Le nombre de paramètres qu’un chercheur peut manipuler est appelé degré de liberté en recherche. Comme la neuroimagerie a un très grand nombre de degrés de liberté, cela augmente le risque de p-hacking. En effet, il est toujours possible de comparer plusieurs approches pour sélectionner la “meilleure”, c’est-à-dire celle qui amène les résultats les plus conformes aux hypothèses de l’équipe de recherche.
Impact des logiciels d’analyse et de l’environnement virtuel
Au-delà des paramètres utilisés dans une analyse, des différences substantielles peuvent venir du choix du logiciel ou de la version du logiciel utilisé (Bowring et al., 2019). Même des changements mineurs peuvent avoir un impact sur les résultats. Et cela n’est pas limité au logiciel de neuroimagerie en tant que tel. Un changement de système d’opération peut lui aussi créer des différences, par exemple, dans une analyse de morphométrie (Gronenschild et al., 2012).
Tailles d’effet#
Show code cell source
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
def sample_data(d, n_samp=1000):
samp1 = np.random.normal(loc=0, scale=1, size=n_samp)
samp2 = np.random.normal(loc=d, scale=1, size=n_samp)
return samp1, samp2
# On génère une série de nombres aléatoires
# avec différentes tailles d'effet
rs = np.random.RandomState(0)
list_d = [0, 0.3, 1, 2]
n_samp = 10000
df1 = pd.DataFrame()
df2 = pd.DataFrame()
for d in list_d:
samp1, samp2 = sample_data(d, n_samp=n_samp)
df1[f'{d}'] = samp1
df2[f'{d}'] = samp2
# On stocke toutes les valeurs avec les paramètres correspondants
# dans un pandas dataframe
df1 = df1.melt(var_name='d')
df1['group'] = 0
df2 = df2.melt(var_name='d')
df2['group'] = 1
df = pd.concat([df1, df2], ignore_index=True)
# On visualise les distributions
import seaborn as sns
sns.set_theme(style='darkgrid')
fig = sns.displot(
df,
x='value',
col='d',
hue='group',
kind='kde',
fill=True,
)
fig.fig.set_dpi(300)
from myst_nb import glue
glue("effect-size-fig", fig.fig, display=False)
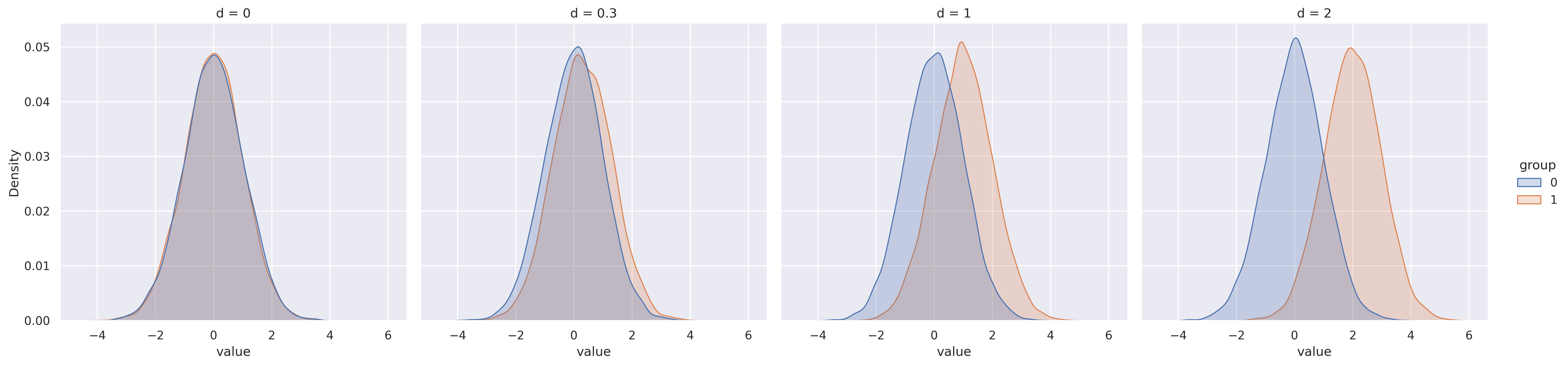
Fig. 113 Illustration de deux distributions de groupes suivant une loi normale pour différentes tailles d’effet mesurées avec le d de Cohen. Figure générée avec du code python à l’aide de la librairie seaborn (cliquer sur + pour voir le code). Cette figure produite par P. Bellec est distribuée sous licence CC-BY 4.0.#
Une autre erreur commune en neuroimagerie est d’interpréter une différence significative comme étant une différence importante. Par exemple, imaginons que l’on trouve une différence significative concernant le volume de l’amygdale entre deux groupes: celui-ci serait réduit chez des personnes sur le spectre de l’autisme par rapport à des individus neurotypiques. Cela signifierait que la différence de la moyenne des distributions est différente, mais il se peut tout à fait qu’un individu sur le spectre ait une amygdale plus grande qu’un individu neurotypique.
Plutôt que de seulement se fier à la significativité, il est important de mesurer la taille de l’effet, c’est-à-dire la différence qui existe entre les deux populations. On peut par exemple considérer la différence des moyennes que l’on divise ensuite par l’écart type des deux populations - une mesure appelée le d de Cohen. Un d de Cohen de 0.1 ou 0.2 est courant pour des différences de groupes entre populations cliniques. Avec ce type de différence, les distributions des deux groupes se chevauchent de manière importante. Un d de Cohen de 2 décrirait pour sa part un effet de groupe très important, où le score de presque tous les membres d’un groupe est inférieur au score de tous les membres de l’autre groupe.
Valeur p et taille d’effet
La valeur p ne nous donne aucune information directe sur la taille de l’effet. Une valeur p peut être très significative, par exemple p<0.000001 simplement parce que l’on compare deux groupes ayant une très grande taille d’échantillon, par exemple N=10000 par groupe. Dans ce cas, même de toutes petites différences peuvent devenir très significatives.
Méthodes incomplètes#

Fig. 114 Cette figure illustre le processus parfois chaotique de développement d’une méthode optimale et la difficulté de communiquer ce processus de manière claire et complète dans la section de méthodes d’un article. Cette figure est tirée de xkcd webcomic, sous licence CC-BY-NC 2.5.#
Le manque de détails dans la section “Méthodes” d’un article peut être un autre obstacle majeur à la reproduction des résultats. Comme les techniques d’analyse utilisées en neuroimagerie sont souvent complexes, il est très rare d’avoir une description complète des méthodes. Il est aussi courant de mettre les étapes qui ont amené à la sélection des méthodes utilisées dans l’article. Le texte d’un article scientifique est généralement écrit de manière à raconter une histoire claire. Le matériel supplémentaire de l’article contient parfois (mais pas toujours) plus de détails méthodologiques ainsi que des expériences supplémentaires, non essentielles au narratif principal de l’article. Il est tout à fait possible que d’autres analyses soient omises entièrement de l’article et que les membres de l’équipe de recherche soient eux-mêmes incapables de retracer le processus qui a amené à la sélection des analyses finales publiées dans l’article.
Des solutions#
Études pré-enregistrées#
Show code cell source
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
# données de https://psyarxiv.com/3czyt
negative_findings = pd.DataFrame({
'source':['articles', 'nouvelles études pré-enregistrées', 'réplications pré-enregistrées'],
'%min':[5, 55, 58],
'%max':[20, 66, 74]
})
# Initialise la figure
fig, ax = plt.subplots(figsize=(6, 4))
print('test')
# Estimation maximale
sns.set_color_codes("pastel")
sns.barplot(x="%max", y="source", data=negative_findings,
label="%max", color="b")
# Estimation minimale
sns.set_color_codes("muted")
sns.barplot(x="%min", y="source", data=negative_findings,
label="%min", color="b")
# Légende
ax.legend(ncol=2, loc="upper right", frameon=True)
ax.set(xlim=(0, 100), ylabel="",
xlabel="Pourcentage de découvertes négatives dans la littérature")
sns.despine(left=True, bottom=True)
fig.set_dpi(300)
from myst_nb import glue
glue("registered-report-fig", fig, display=False)
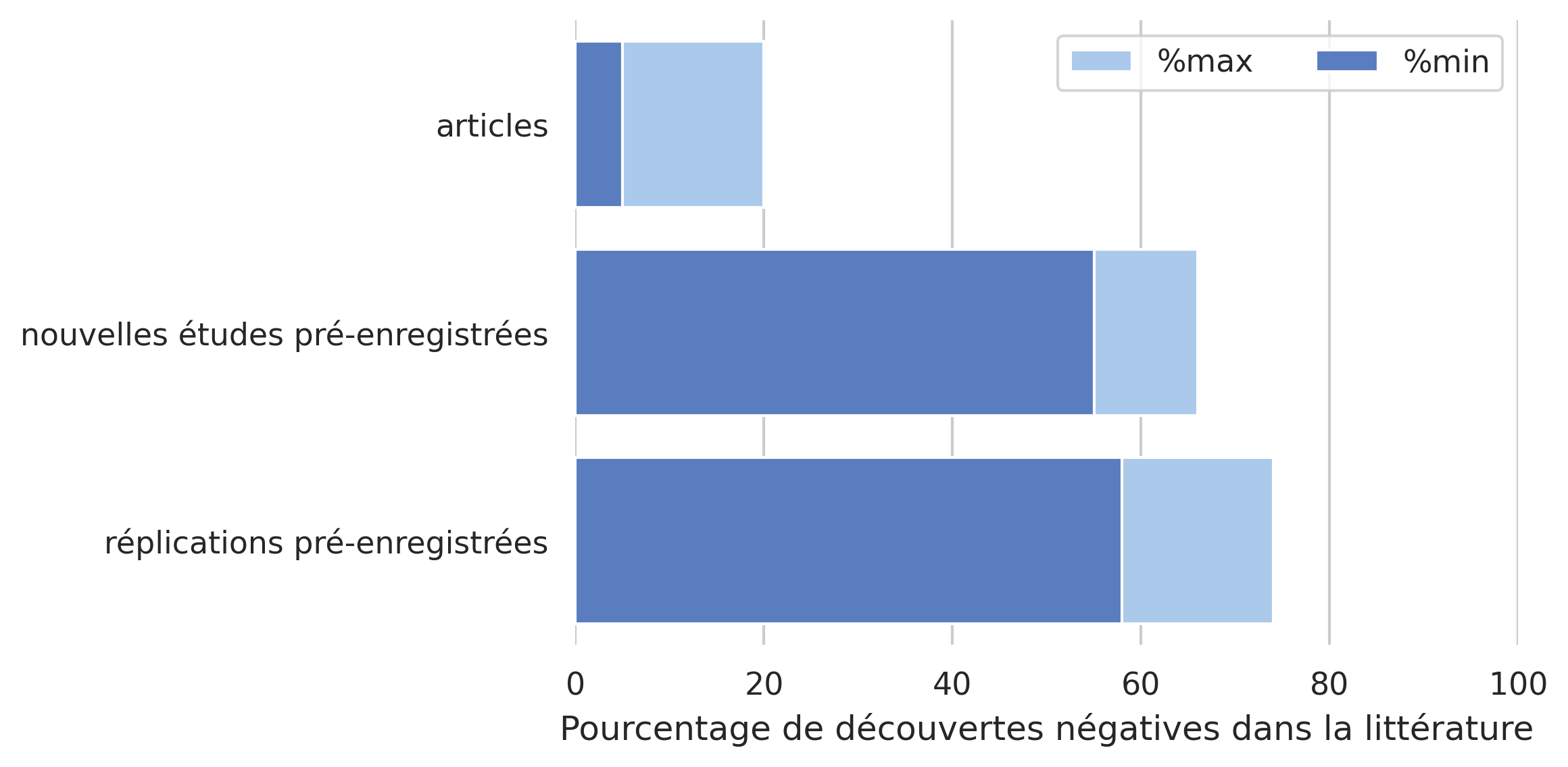
Fig. 115 Pourcentage de “découvertes négatives” dans la littérature. Les découvertes négatives viennent d’études pour lesquelles les analyses ne confirment pas les hypothèses de recherche. On compare ici des articles traditionnels avec des études pré-enregistrées portant sur de nouvelles hypothèses de recherche, ainsi que des études pré-enregistrées portant sur des études de réplication de résultats déjà publiés. Pour chaque pourcentage, une valeur estimée minimale et maximale est fournie. Statistiques tirées de Allen et Mehler, 2018 sur 127 études pré-enregistrées. Figure générée avec du code python à l’aide de la librairie seaborn (cliquer sur + pour voir le code). Cette figure produite par P. Bellec est distribuée sous licence CC-BY 4.0.#
Une première idée qui gagne en popularité pour répondre à la crise de la reproductibilité est ce que l’on appelle une étude pré-enregistrée. Un des problèmes dans le cercle présenté en Fig. 110, c’est qu’on choisit de ne publier que quand on connaît les résultats. Comme publier un article est un processus long et coûteux (certains journaux demandent plusieurs milliers de dollars de frais de publication) et que les résultats négatifs sont peu valorisés, il est compréhensible que l’équipe de recherche décide simplement de passer au prochain projet plutôt qu’investir dans la publication d’un résultat négatif. Une manière d’éliminer ça, c’est de soumetre la publication avec les hypothèses et les plans d’analyse, avant de recueillir les données. Cela permet aux reviewers de critiquer la conception de l’étude avant qu’elle soit terminée, et permet donc de modifier le protocole de recherche si nécessaire. L’article est alors accepté, quelque soit le résultat de l’étude. Si les résultats ne correspondent pas aux hypothèses, l’article serait déjà accepté et publié tout de même. Cela ne veut pas dire qu’on ne peut pas présenter des nouvelles analyses auxquelles on n’avait pas pensé avant. Celles-ci sont alors présentées (correctement) comme exploratoires, plutôt que confirmatoires. En d’autres termes, cette approche élimine le HARKing, et il semble en pratique que cette approche fonctionne (voir Fig. 115).
Code#

Fig. 116 Cette figure illustre les avantages d’automatiser les analyses scientifiques à l’aide de code (de manière métaphorique). Cette figure est tirée de xkcd webcomic, sous licence CC-BY-NC 2.5.#
Une autre solution pour rendre les analyses scientifiques en neuroimagerie plus reproductible est d’apprendre à coder. Automatiser les analyses permet de les rendre plus faciles à reproduire pour quiconque. Il peut y avoir des erreurs dans le code, mais elles peuvent être vues et réparées par d’autres. Les analyses qui ne reposent pas sur du code représentent un obstacle majeur à la reproductibilité. Pour être vraiment utile, le code d’une analyse doit être partagé publiquement. Ce code constitue alors un artefact de recherche très important, beaucoup plus détaillé et spécifique que la section méthodologique d’un article. Beaucoup de gens utilisent la plateforme Github pour partager des éléments de code et aussi afin de partager les modifications qui y sont faites avec le temps. Il est aussi possible d’archiver une version du code sur une plateforme comme zenodo qui fournit un identifiant unique pour ce code, comme pour un article. Si le code est de haute qualité et réutilisable, il est même possible de publier un article sur ce code dans un journal comme le Journal of Open Source Software.
Partage de données#
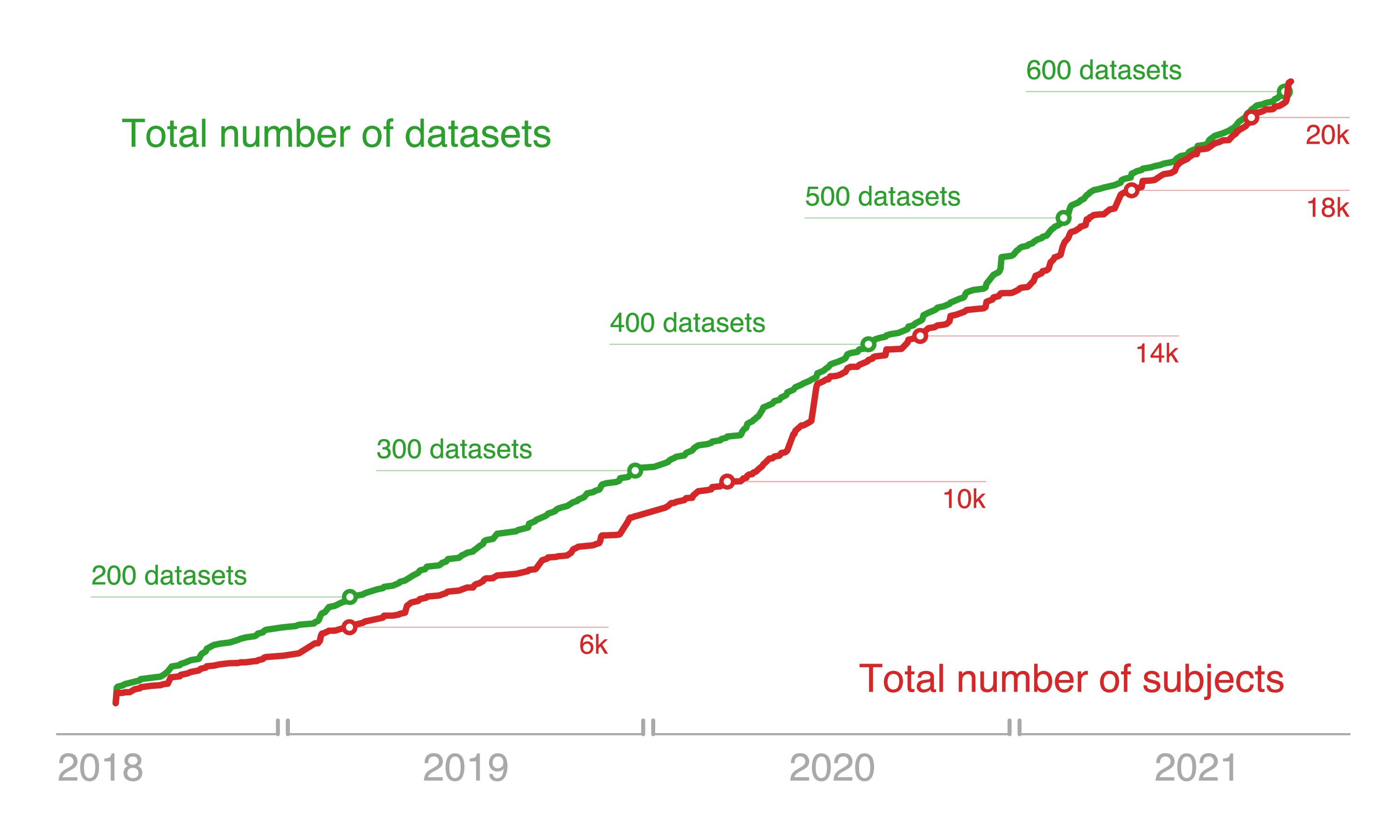
Fig. 117 Nombre de jeux de données ouverts en neuroimagerie et nombre de participants disponibles sur la plateforme de partage de données openneuro. Figure tirée de Markiewicz et al., 2021 sous licence CC-BY 4.0.#
Une autre solution pour améliorer la reproducibilité est de partager les données de recherche. La Fig. 117 illustre l’adoption rapide de cette pratique dans la communauté de recherche en neuroimagerie. Partager ses données permet à d’autres laboratoires de répliquer les analyses ou essayer d’autres méthodes. Cela permet aussi au laboratoire d’origine de disposer d’une archive bien organisée pour de futurs projets. Le partage des données humaines est en revanche rendu complexe dans certaines parties du monde (comme le Québec) à cause de considérations éthiques ou bien légales. Il est en revanche toujours possible de partager des cartes statistiques de groupe, par exemple en utilisant une plateforme comme neurovault.
Partage d’environnement#
Des outils existent également pour partager un environnement de travail, ce qui est possible gratuitement grâce aux technologies libres. Il existe diverses solutions. Le language python permet de décrire un ensemble de dépendances (avec versions) au moyen d’un simple fichier texte requirements.txt. Certaines versions de linux comme neurodebian ont également un grand nombre d’outils de neuroimagerie prêts à l’installation, incluant des fonctionnalités de contrôle des versions. Les containers sont une autre famille de solutions qui permettent de partager un ensemble de librairies ainsi que le système d’exploitation. Des variantes de containers ont été spécifiquement développées pour les neurosciences cognitives, comme neurodocker. Un dernier exemple est mybinder qui permet d’importer un container avec toutes les dépendances d’un projet et de ré-exécuter ce code dans un fureteur internet, sans avoir à installer quoi que ce soit. Pour la version en ligne de ces notes de cours, il y a une petite fusée en haut à droite qui démarre la plateforme mybinder. Comme les notes de cours utilisent des données ouvertes pour beaucoup de figures, il est possible de reproduire (et modifier) les figures du cours de cette manière.
Puissance statistique et meilleures pratiques#
Certains articles se concentrent sur la formulation de « guides » des meilleures pratiques pour différentes méthodes de recherche. Le domaine des neurosciences cognitives a par exemple un guide baptisé COBIDAS (Nichols et al., 2017), qui a également une version pour la MEG (Pernet et al., 2020). Ce type de guide permet de sélectionner des méthodes qui sont non seulement reproductibles, mais idéalement aussi robustes et pourront être répliquées avec des méthodes ou des données différentes. Un point important à considérer est celui de la puissance statistique d’une étude. Alors que la valeur p nous informe sur la fréquence de faux positifs, c’est-à-dire une détection faite en l’absence de signal, la puissance statistique nous informe sur la fréquence des faux négatifs, c’est-à-dire le signal qu’on n’arrive pas à détecter. Pour qu’un résultat soit reproductible, il est critique que la puissance statistique du test soit élevée. Avec le modèle linéaire général, la puissance statistique dépend de la taille d’effet, du nombre de participants dans l’étude ainsi que du taux de faux positifs p du test. Voir cette page internet pour expérimenter avec différents paramètres.
Conclusions#
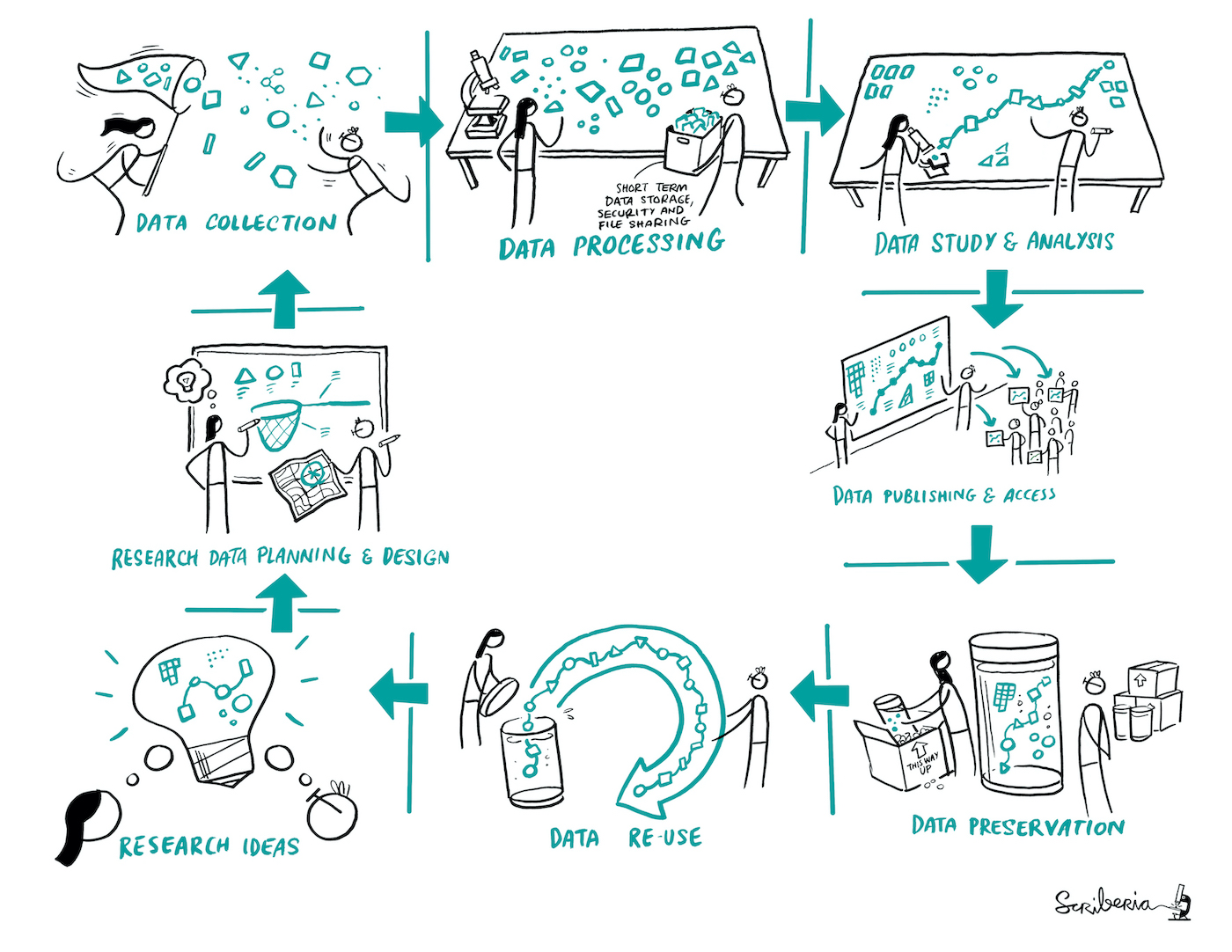
Fig. 118 Un cycle de découvertes en recherche qui inclut la préservation et la réutilisation des données. Figure par scriberia dans le cadre du livre The Turing way sous licence CC-BY 4.0, DOI: 10.5281/zenodo.3332807.#
Dans ce chapitre, on a vu:
certaines pratiques de recherche douteuses qui peuvent amener à des découvertes scientifiques non-reproductibles.
des aspects de la recherche en neuroimagerie qui sont particulièrement problématiques:
sensibilité à de nombreux paramètres
manque de quantification des tailles d’effet
difficultés à décrire les méthodes de manière complète dans un article.
des nouvelles pratiques qui permettent d’améliorer la reproductibilité de la science:
études pré-enregistrées
partage de code, données et environnement
meilleures pratiques d’analyse.
On voit aujourd’hui émerger une nouvelle approche de découverte scientifique qui inclut notamment le partage et la réutilisation de données, ce qui va amener une science plus reproductible et fiable (Fig. 118).
Exercices#
Exercice 1
Vrai/faux. La significativité des résultats dans une étude de neuroimagerie peut être impactée par…
le logiciel que l’on utilise pour tester l’hypothèse de recherche.
les paramètres que l’on choisit pour analyser les données, comme par exemple la quantité de lissage spatial.
le système d’exploitation de l’ordinateur utilisé pour effectuer les analyses.
la version du système d’exploitation de l’ordinateur utilisé pour effectuer les analyses.
Exercice 2
Vrai/faux. La puissance statistique…
indique la probabilité de détecter un effet avec une procédure statistique.
contrôle le taux de faux positifs.
décroît avec le nombre de sujets dans l’étude.
croît avec le seuil de significativité choisi pour l’étude (seuil p).
décroît avec la taille de l’effet testé.
Exercice 3
Choisissez la bonne réponse. Pour pouvoir reproduire exactement un résultat de recherche, il est nécessaire d’avoir accès…
aux données utilisées dans l’étude
au code utilisé pour générer les résultats de l’étude, s’il existe
à l’environnement (version des logiciels) utilisé dans l’étude
Réponses 1 et 2.
Réponses 1, 2 et 3.
Exercice 4
Choisissez la bonne réponse. Parmi les procédures suivantes, laquelle (lesquelles) n’est (ne sont) pas statistiquement valide(s)?
Présenter comme hypothèse d’une étude une observation faite seulement après l’obtention et l’analyse des données.
Redéfinir les critères d’exclusion des participants en se basant sur la qualité des données, et ce, après avoir effectué une première analyse des données.
Présenter dans une étude uniquement les résultats d’un sous-groupe du devis de recherche original parce que ce sous-groupe est le seul qui présente des résultats significatifs.
Aucune des trois procédures présentées ci-haut n’est valide.
Réponses 2 et 3.
Exercice 5
Une équipe de recherche a effectué une étude par activation en imagerie optique chez des nouveaux-nés. Le comité d’éthique n’a pas permis le partage des données de recherche. Proposez deux actions concrètes pour améliorer malgré tout la reproductibilité de l’étude.
Exercice 6
Une équipe de recherche compare le volume de différentes régions du cerveau entre deux groupes de sujets (N=20 par groupe): des sujets en santé ainsi que des sujets présentant des signes de dépression. Pour cela, l’équipe effectue une analyse par volumétrie automatisée utilisant un atlas comprenant 90 régions et teste l’effet de groupe sur chaque région indépendamment avec un modèle de régression qui inclut l’âge et le sexe des participants. Le seuil de significativité est fixé à p<0.05. Le seul test significatif est identifié au niveau de l’amygdale (p=0.041). La conclusion de l’étude est “Le volume de l’amygdale est plus petit chez les individus présentant des signes de dépression, mais le volume de l’hippocampe est normal”. Identifiez trois problèmes majeurs avec cette conclusion.